
こんにちは、前回はPythonでGoogleサーチコンソールのデータをBigQueryへロードする方法についてご紹介しました。
前回はPythonのプログラムをローカルで実行していましたが、
今回はGCPの各サービスを利用して、日時で自動でデータのロードを行う方法についてご紹介します!
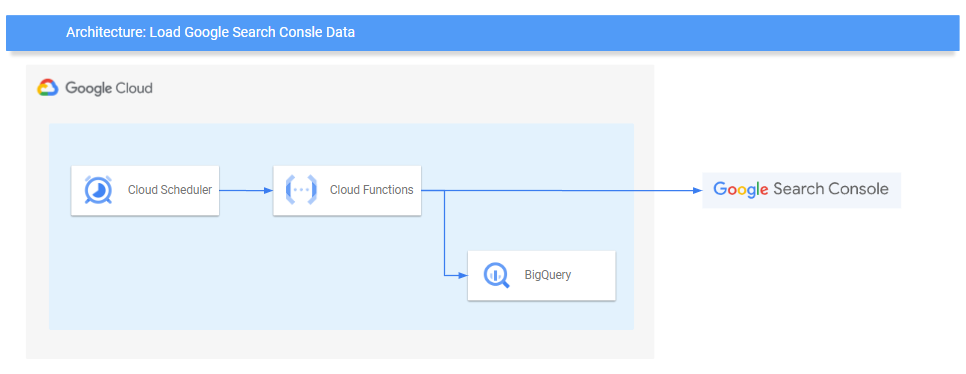
今回作るもの
今回作成するシステム構成図は以下の通りです。
Pythonのプログラムの実行はCloud Functionsで実行します。
Cloud FunctionsはHTTPトリガーを設定し、スケジュール実行をCloud Schedulerで制御します。
search-consoleサービスアカウント
前回の記事で作成した、search-consoleサービスアカウントを引き続き利用します。
今回利用サービスが増えるため、ロールを新しく付与します。
以下のロールを設定しましょう。
- BigQuery ジョブユーザー
- BigQuery データ編集者
- Cloud Functions サービス エージェント
- Cloud Functions 起動元
- Cloud Scheduler ジョブ実行者
Cloud Functionsの設定
関数の作成
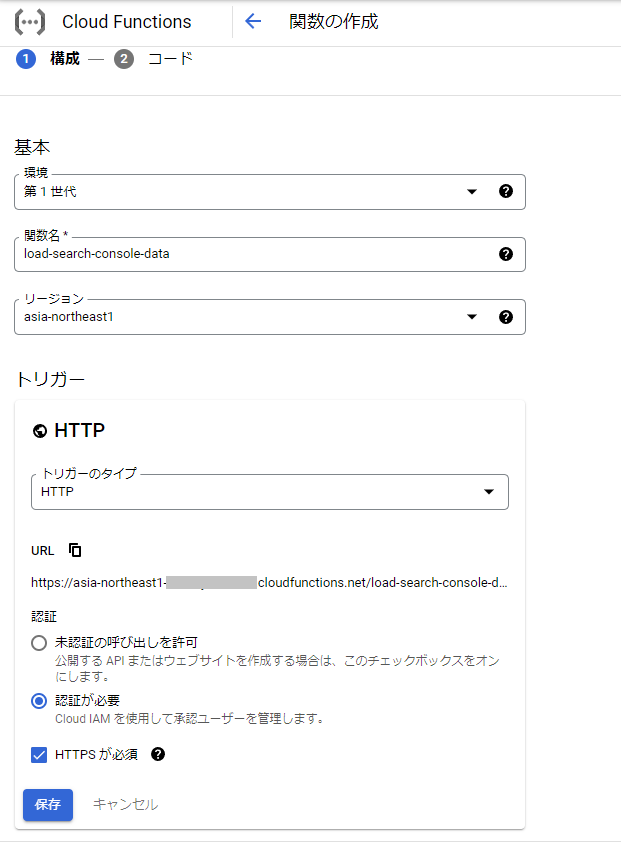
GCPコンソールのハンバーガーメニューから、[Cloud Functions] > [関数の作成]を選択します。
「基本」の設定は以下のように設定します。
- 環境: 第1世代
- 関数名: load-search-console-data
- リージョン: asia-northeast1
- トリガー: HTTP(認証が必要、HTTPSが必須にチェック)
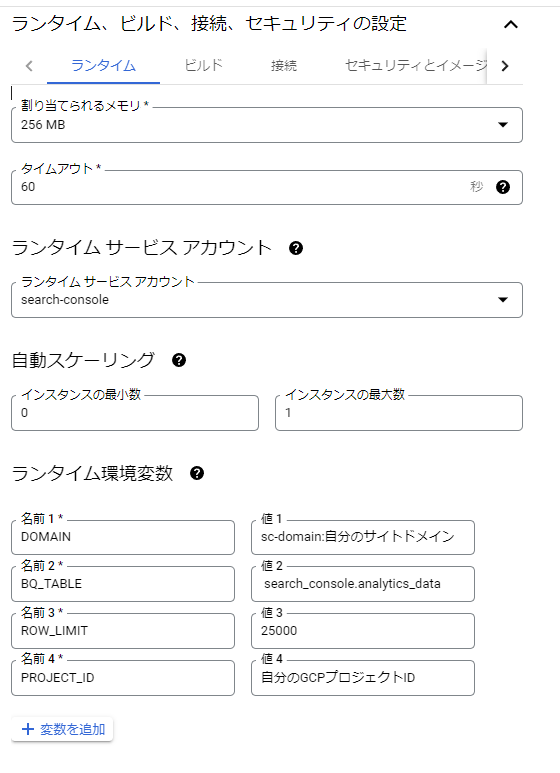
「ランタイム、ビルド、接続、セキュリティの設定」は、ランタイムの設定を以下のように設定します。
- ランタイム サービス アカウント: search-console
- 自動スケーリング: インスタンス最大数を1
- 環境変数
- DOMAIN: sc-domain:自分のサイトドメイン
- BQ_TABLE: search_console.analytics_data
- ROW_LIMIT: 25000
- PROJECT_ID:自分のGCPプロジェクトID
次へを押すとランタイムとソースコードを入力する画面に遷移します。
以下を入力して、[デプロイ]を押下しましょう。
- ランタイム: Python3/8
- ソースコード: インラインエディタ(後述のソースをコピペ)
- エントリポイント: execute

main,py
from datetime import datetime, date, timedelta import os from urllib.parse import unquote from google.cloud import bigquery from googleapiclient.discovery import build DOMAIN = os.environ['DOMAIN'] PROJECT_ID = os.environ['PROJECT_ID'] BQ_TABLE = os.environ['BQ_TABLE'] ROW_LIMIT = os.environ['ROW_LIMIT'] DIMENSIONS = ['date', 'query', 'page', 'device', 'country'] class SearchConsoleToBigQueryClient: def __init__(self): self.__webmasters = build('webmasters','v3',) self.__bq_client = bigquery.Client(project=PROJECT_ID) def __format_json( self, api_response: list): list_ = [] for row in api_response: list_.append( { 'date': row['keys'][0], 'query': row['keys'][1].split(' '), 'page': unquote(row['keys'][2]), 'device': row['keys'][3], 'country': row['keys'][4], 'clicks': row['clicks'], 'impressions': row['impressions'], 'ctr': float(row['ctr']), 'position': float(row['position']), } ) return list_ def get_analytics_data( self, start_date: date, end_date: date=None): if end_date is None: end_date = start_date body = { 'startDate': start_date.strftime(r'%Y-%m-%d'), 'endDate': end_date.strftime(r'%Y-%m-%d'), 'dimensions': DIMENSIONS, 'rowLimit': ROW_LIMIT, 'startRow': 0, } response = self.__webmasters.searchanalytics().query(siteUrl=DOMAIN, body=body).execute() try: rows = response['rows'] except KeyError: raise Exception('結果が取得されませんでした。') json = self.__format_json(rows) if len(json) == ROW_LIMIT: raise Exception('結果がROW_LIMITの値に達しました。{}'.format(ROW_LIMIT)) return json def bq_load( self, data: list, partition_date: date=None, write_disposition: str='WRITE_TRUNCATE'): if partition_date is None: destination='{}'.format(BQ_TABLE) else: destination = '{}${}'.format(BQ_TABLE, partition_date.strftime(r'%Y%m%d')) bq_config = bigquery.LoadJobConfig() bq_config.write_disposition = write_disposition job = self.__bq_client.load_table_from_json( json_rows=data, destination=destination, num_retries=1, project=PROJECT_ID, job_config=bq_config ) job.result() def load_analytics_data( self, target_date: datetime): data = self.get_analytics_data(target_date) self.bq_load(data, target_date) def execute(request): # 4日前のデータを取得する dt_now = date.today() - timedelta(days=4) print(dt_now) client = SearchConsoleToBigQueryClient() client.load_analytics_data(dt_now) return {} if __name__ == '__main__': execute(None)
requirements.txt
google-api-python-client==2.41.0 google-cloud-bigquery==2.34.2
前回の記事からのプログラムの変更点
前回からの変更点は主に以下の通りです。
- サービスアカウントの認証をJSONではなくCloud Functionsの設定で行うようにした
- 各種定数をなどを環境変数にした
execute()メソッドを用意し、HTTPトリガーのエントリポイントとした- 日付を固定で実行日の4日前とした
Google Search Console APIは3,4日前の情報しか取得できないとのことなので、常に4日前の情報を取得するようにしています。
Cloud Schedulerの設定
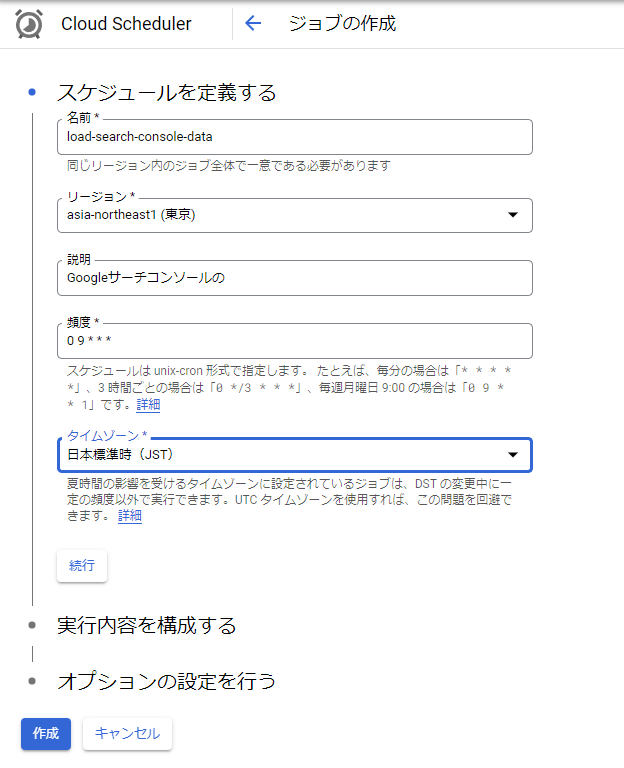
それでは次にCloud Functionsを呼び出しするCloud Schedulerの設定をします。
GCPコンソールのハンバーガーメニューから、[Cloud Scheduler] > [ジョブを作成] と進みます。
はじめの「スケジュールを定義する」では以下の通り設定します。
- 名前: load-search-console-data
- リージョン: asia-northeast1(東京)
- 説明: 任意
- 頻度: 0 9 * * *
- タイムゾーン: JST
次の「実行内容を構成する」では以下の通り設定します。
- ターゲットタイプ: HTTP
- URL: 作成したCloud FunctionsのトリガーURL
- HTTPメソッド: GET
- Authヘッダー: OIDC トークンを追加
- サービスアカウント: search-console
- 対象: 作成したCloud FunctionsのトリガーURL
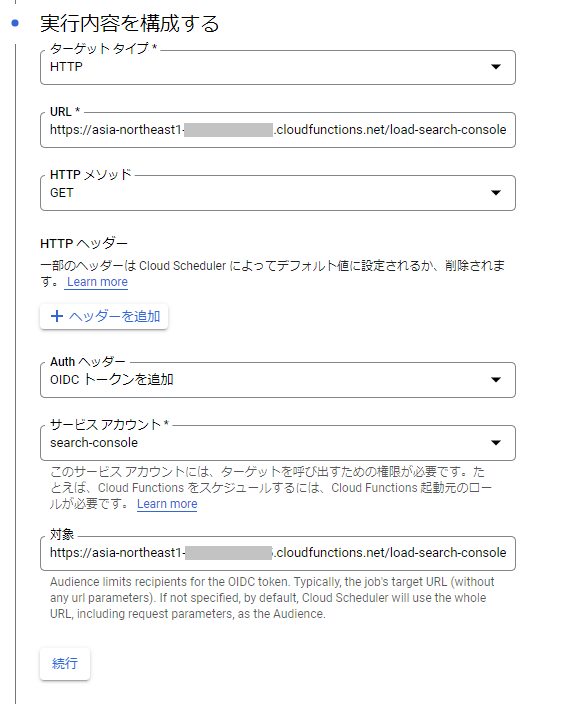
オプションの設定は特に変更せず、ジョブを作成します。
以上、これで毎日9時にCloud SchedulerからCloud Functionsの関数が実行され、
Google Search ConsoleのデータがBigQueryにロードされるようになります!
まとめ
以上、今回はCloud FunctionsでGoogle Search ConsoleのデータをBigQueryに日次でロードする方法についてご紹介しました。
データ収集の自動化もデータエンジニアの業務の一つ。Cloud Functionsに限らず様々な手段が考えられますが、今回は当ブログのデータ収集、つまりは個人利用のため、コストが最小限の方法で実装してみました。
Googleサーチコンソールのデータの活用についてはまた別の機会でご紹介できればと思います。

